April recap: Introduction to Text Mining with R
Our April Event!
The April R-Ladies meetup was held on April 19th at Drexel. Thanks again to Drexel for hosting us and to DataCamp and the R consortium for sponsoring us!
Our topic was an introduction to text mining in R using the first two chapters of “Text Mining with R” by fellow R-Lady(!) Julia Silge and David Robinson.

There was a great group - including some new faces!
Amy took us through the key concepts of the chapter and then we broke into groups to do some exercises together. Here is an example analysis that we completed!
book.id <- 51713
kafka <- gutenberg_download(51713)## Determining mirror for Project Gutenberg from http://www.gutenberg.org/robot/harvest## Using mirror http://aleph.gutenberg.orgdata(stop_words)
tidy_kafka <- kafka %>%
mutate(linenumber = row_number()) %>%
unnest_tokens(word, text)%>%
anti_join(stop_words)## Joining, by = "word"kafka_sentiment <- tidy_kafka %>%
inner_join(get_sentiments("bing")) %>%
count(index = linenumber %/% 10, sentiment) %>%
spread(sentiment, n, fill = 0) %>%
mutate(sentiment = positive - negative)## Joining, by = "word"# PLOT
ggplot(kafka_sentiment, aes(index, sentiment, fill = sentiment > 0)) +
scale_fill_discrete(c("light blue","red")) +
geom_col(show.legend = FALSE) +
ggtitle("Sentiment in Kafka's Metamorphosis") +
theme_bw()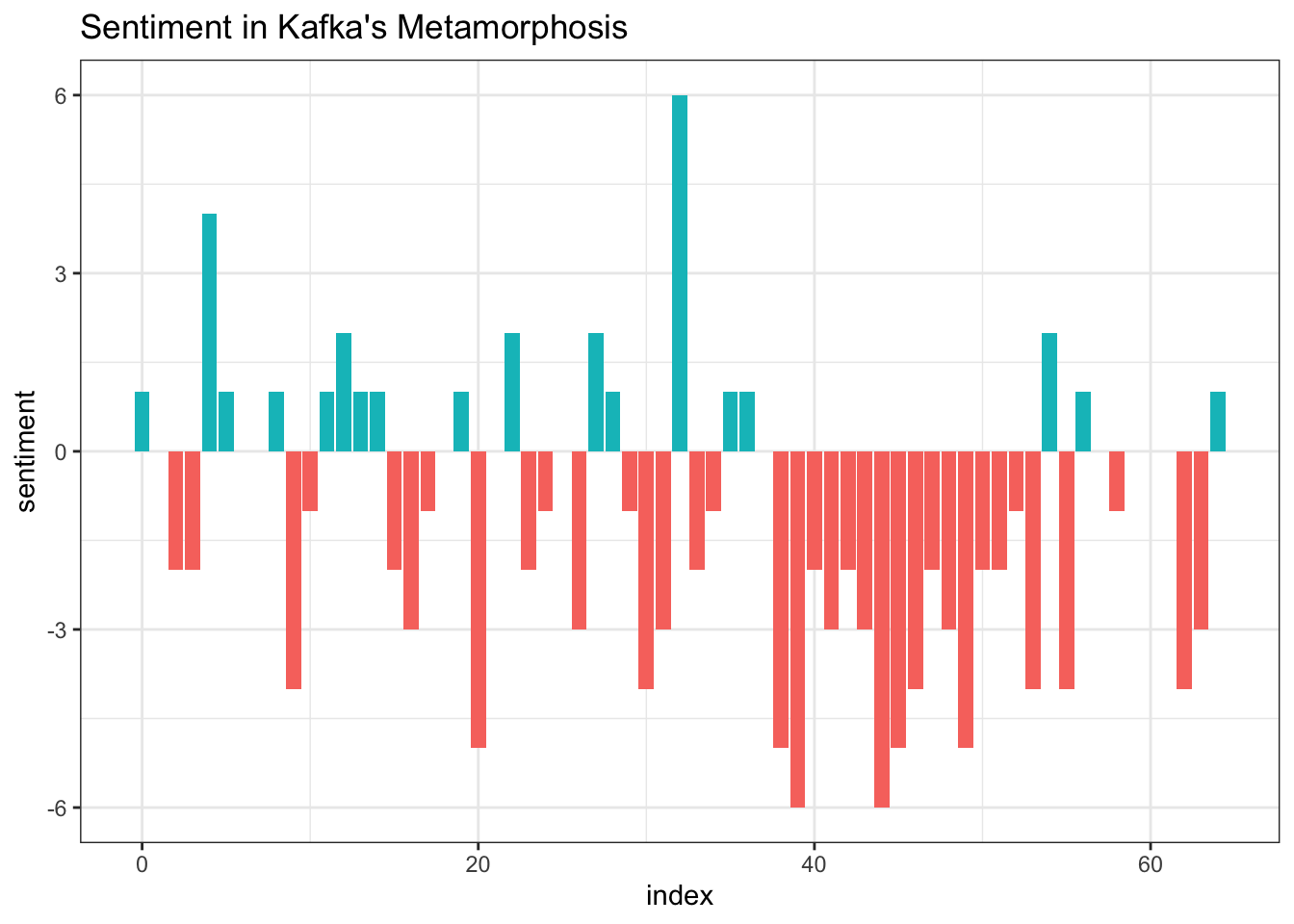
Next, we had an awesome lightning talk from Darina that went into TF-IDF. TF is Term Frequency and IDF is Inverse Document Frequency. Check out her slides to learn more.

Darina presents on TF-IDF
For more information
The materials from April are posted on GitHub:
https://github.com/rladies/meetup-presentations_philadelphia
For those who want to learn more, I recommend continuing on in the excellent book, “Text Mining with R”:
https://www.tidytextmining.com
This post was authored by Alice Walsh. For more information contact philly@rladies.org